Hadoop zookeeper高可用HA配置
**
HDFS的高可用(HA)的实现方式:
**
一种是将NN维护的元数据保存一份到NFS上,当NN故障,可以通过另一台NNe读取NFS目录中的元数据备份进行恢复工作,需要手动进行操作,并不是真正意义上的HA方案。
另一种是准备一台备用NN节点,通过定期下载NN的元数据和日志文件来备份,当NN故障时,可以通过这台进行恢复,由于主备节点元数据和日志并不是实时同步,所以会丢失一些数据。
前两种方案都不是很理想,社区提供一种更好的方案,基于QJM(Qurom Journal Manager)的共享日志方案。QJM的基本原理是NN(Active)把日志写本地和2N+1(奇数)台JournalNode上,当数据操作返回成功时才写入日志,这个日志叫做editlog,而元数据存在fsimage文件中,NN(Standby)定期从JournalNode上读取editlog到本地。在这手动切换的基础上又开发了基于Zookeeper的ZKFC(ZookeeperFailover Controller)自动切换机制,Active和Standby节点各有ZKFC进程监控NN监控状况,定期发送心跳,当Active节点故障时Standby会自动切换为ActiveNode,本次就用的此方案。如下图所示:
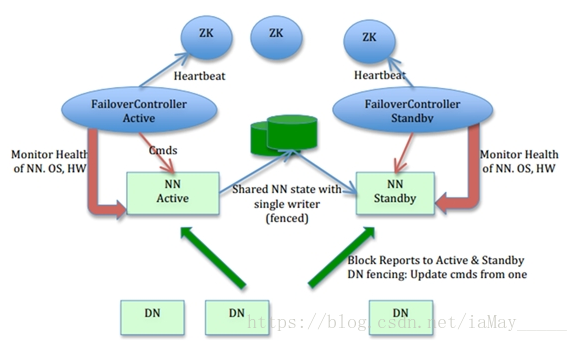
**
zookeeper安装
**
hadoop安装根据前一篇部署即可 删除所所有节点tmp下数据 配置完成后重新 初始化即可
————————————————————————————————————
zookeeper需要jdk环境 在配置正确的情况下无法启动 一般是没有jdk 安装重启即可
安装在hadoop目录下即可
需要三台zookeeper节点
##############################################
编辑节点信息
vim conf/zoo.cfg
————————————————————————————————————————————————————————————
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=172.25.15.7:2888:3888
server.2=172.25.15.8:2888:3888
server.3=172.25.15.9:2888:3888
————————————————————————————————————————————————————————————
创建数据目录 并创建server id文件
mkdir /tmp/zookeeper
echo 3 > myid
与zoo.cfg中配置对应即可
##############################################################
开启服务
三台主机全部开启
[root@server2 zookeeper-3.4.9]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看状态 中间的主机为leader 其他为follower
————————————————————————————————————————————————————————————
[root@server3 zookeeper-3.4.9]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
————————————————————————————————————————————————————————————
[root@server2 zookeeper-3.4.9]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
################################################################
链接zookeepre查看
[root@server3 zookeeper-3.4.9]# bin/zkCli.sh -server 127.0.0.1:2181
Connecting to 127.0.0.1:2181
————————————————————————————————————————————————————————————————
查看数据
[zk: 127.0.0.1:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 1] get /zookeeper/quota
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
配置hadoop
在server1上配置
[root@server1 hadoop]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.15.7:2181,172.25.15.8:2181,172.25.15.9:2181</value>
</property>
</configuration>
————————————————————————————————————————————————————————————————————————
[root@server1 hadoop]# vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.15.6:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.15.6:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.15.10:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.15.10:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.15.7:8485;172.25.15.8:8485;172.25.15.9:8485/masters</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.master</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
启动服务
3. 启动 hdfs 集群(按顺序启动)
1)在三个 DN 上依次启动 zookeeper 集群
$ bin/zkServer.sh start
[hadoop@server2 ~]$ jps
1222 QuorumPeerMain
1594 Jps
2)在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
$ sbin/hadoop-daemon.sh start journalnode
[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1594 Jps3)格式化 HDFS 集群
$ bin/hdfs namenode -format
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
$ scp -r /tmp/hadoop-hadoop 172.25.0.5:/tmp
3) 格式化 zookeeper (只需在 h1 上执行即可)
$ bin/hdfs zkfc -formatZK
(注意大小写)
4)启动 hdfs 集群(只需在 h1 上执行即可)
$ sbin/start-dfs.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查看各个节点信息
master节点
[root@server1 hadoop]# jps
3043 DFSZKFailoverController
2755 NameNode
3144 Jps
——————————————————————————
数据节点
[root@server2 hadoop]# jps
2289 JournalNode
2355 Jps
2198 DataNode
1705 QuorumPeerMain
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
浏览器查看
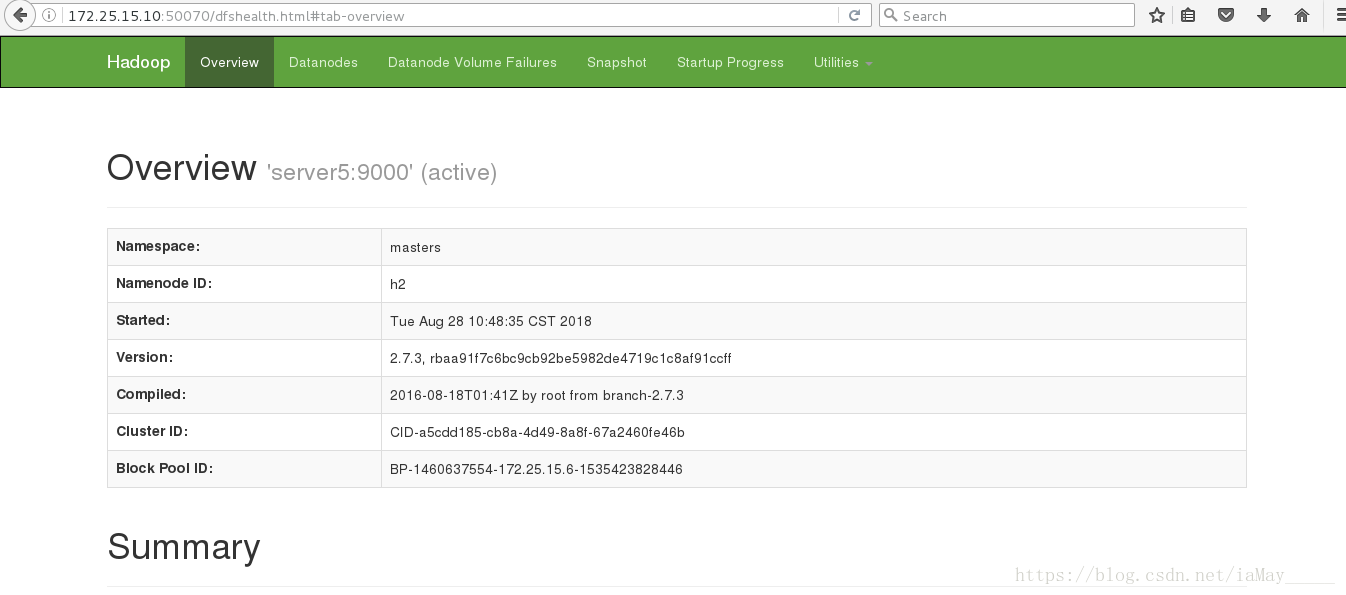
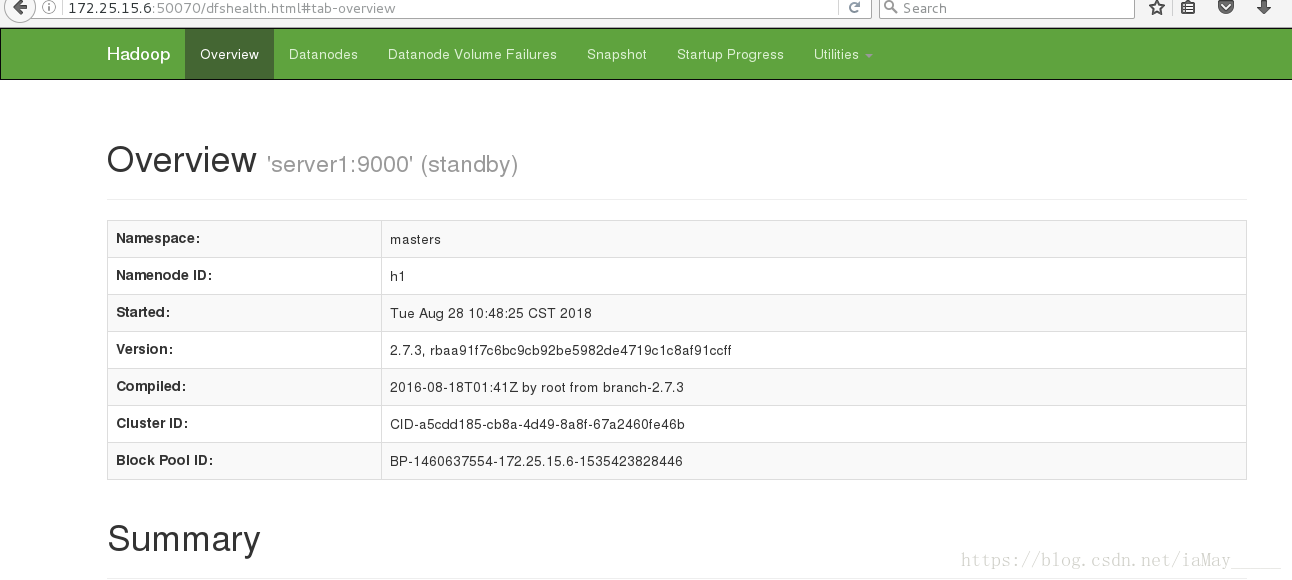
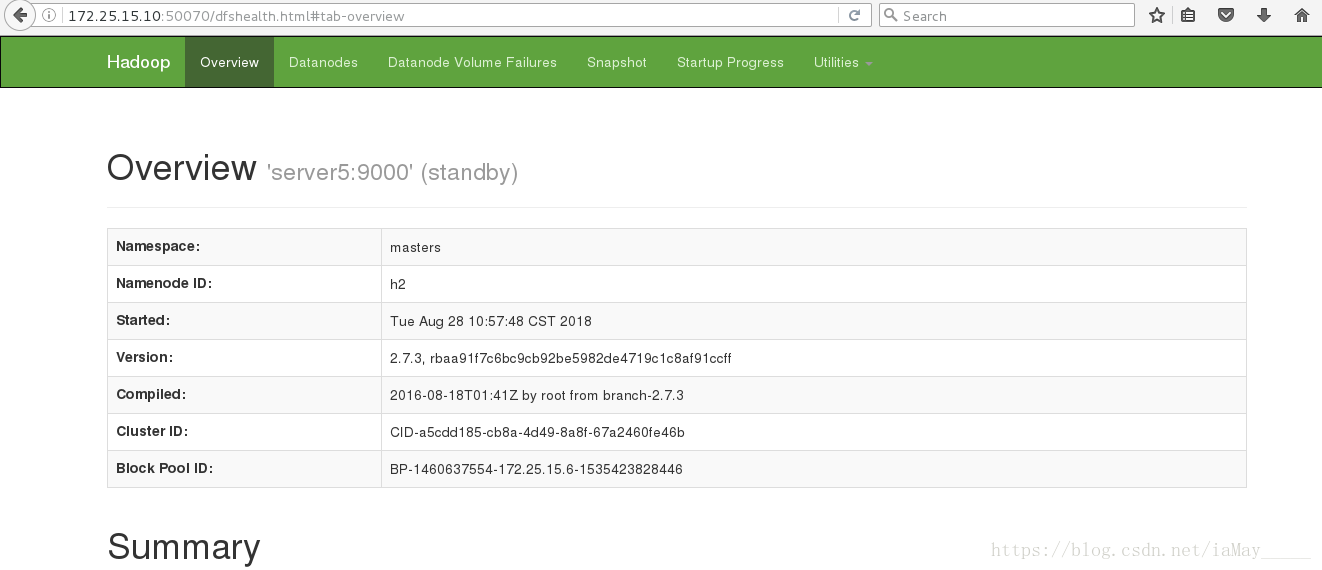
ok 在同一时间只有一台主机active
测试高可用 停掉server5的namenode 测试数据是否同步
[root@server5 mnt]# jps
1808 Jps
1705 DFSZKFailoverController
1613 NameNode
[root@server5 mnt]# kill -9 1613
- 1
- 2
- 3
- 4
- 5
- 6
ok server1自动接管服务
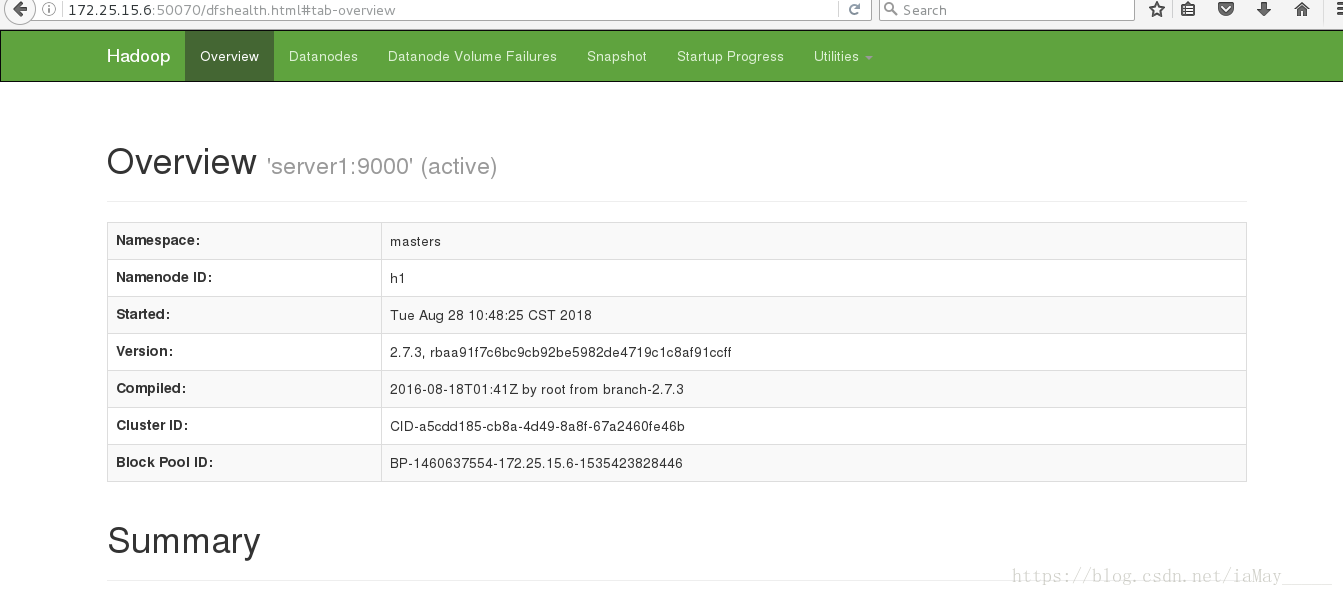
重新开启server5 namenode服务即可
[root@server5 hadoop]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-server5.out
- 1
- 2
- 3
yarn 的高可用:
修改配置文件
——————————————————————————————————————————————————————————————————
[root@server5 hadoop]# cat etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
——————————————————————————————————————————————————————————————————————————
[root@server5 hadoop]# cat etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@server5 hadoop]# cat etc/hadoop/yarn-
yarn-env.cmd yarn-env.sh yarn-site.xml
[root@server5 hadoop]# cat etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.15.6</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.15.10</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.15.7:2181,172.25.15.8:2181,172.25.15.9:2181</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
启动服务
启动 yarn 服务
$ sbin/start-yarn.sh
[hadoop@server1 hadoop]$ jps
6559 Jps
2163 NameNode
1739 DFSZKFailoverController5127 ResourceManager
RM2 上需要手动启动
$ sbin/yarn-daemon.sh start resourcemanager
[hadoop@server5 hadoop]$ jps
1191 NameNode
3298 Jps
1293 DFSZKFailoverController
2757 ResourceManager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
最好是把 RM 与 NN 分离运行,这样可以更好的保证程序的运行性能。但实验环境可以放在一起测试。
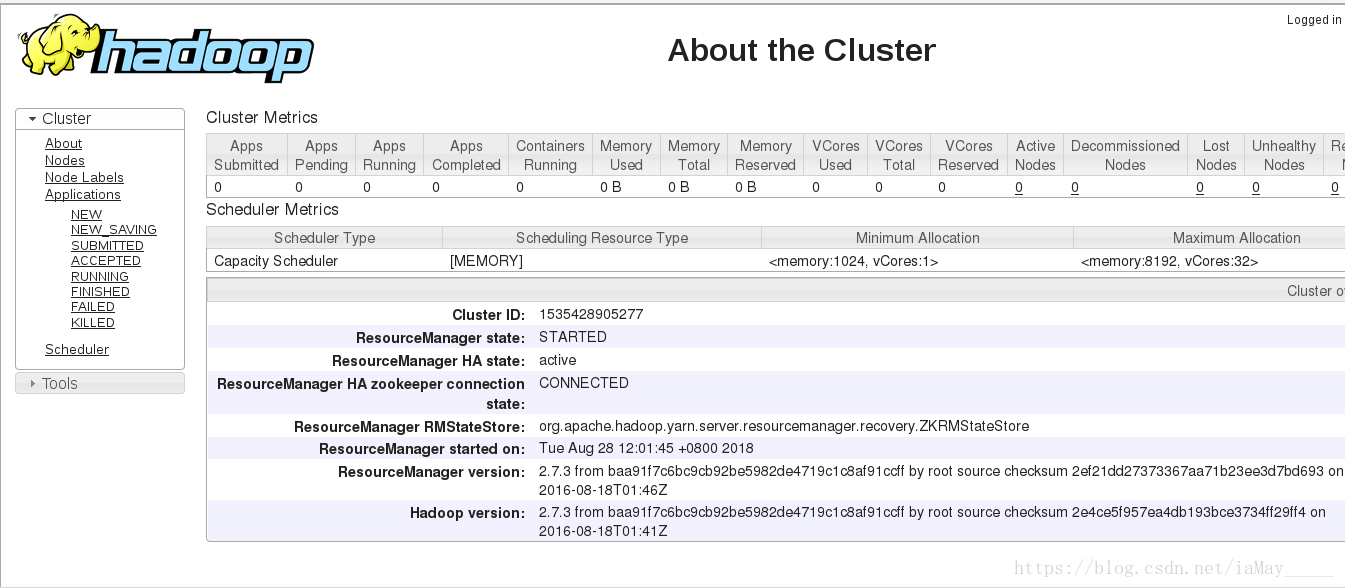
打开浏览器查看数据
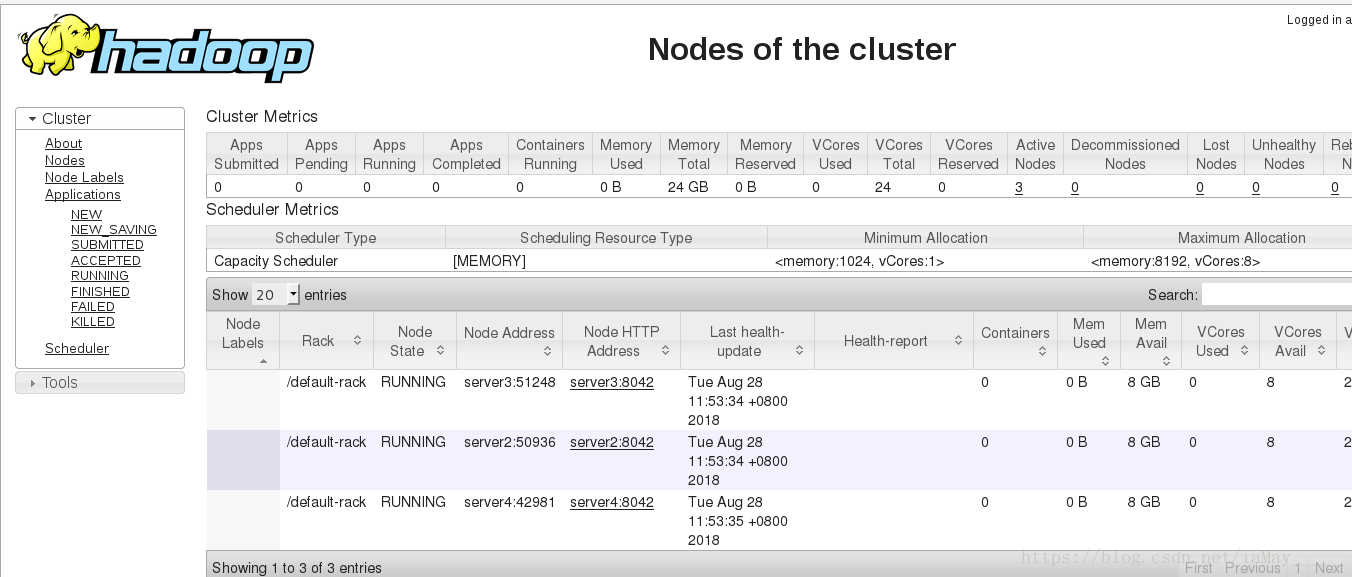
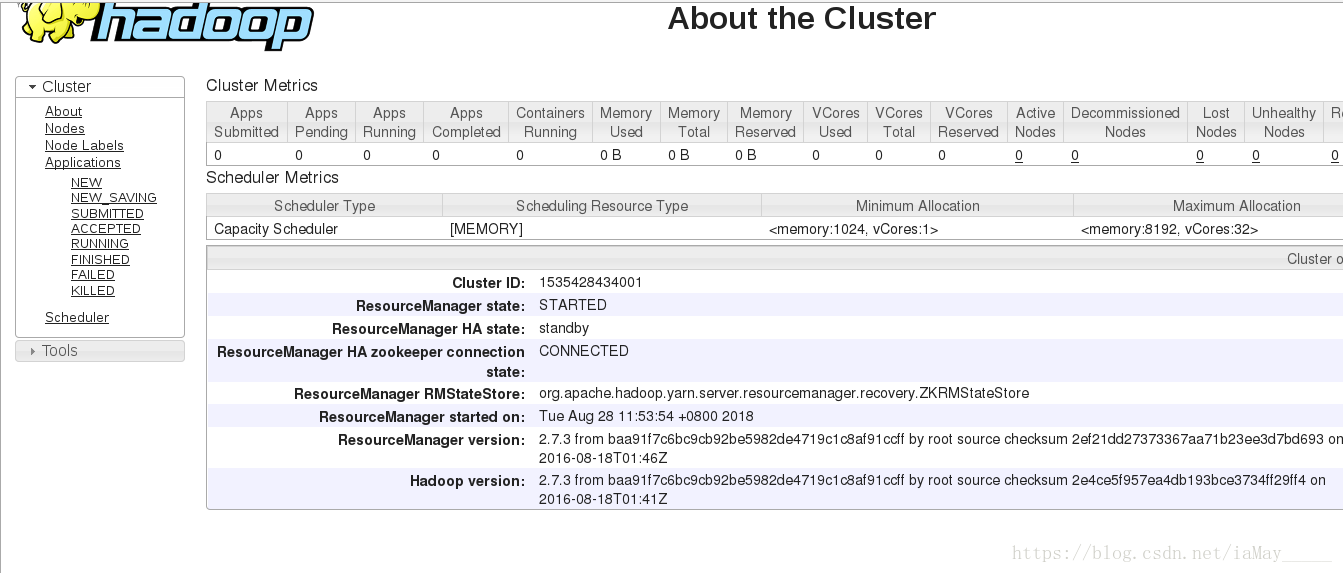
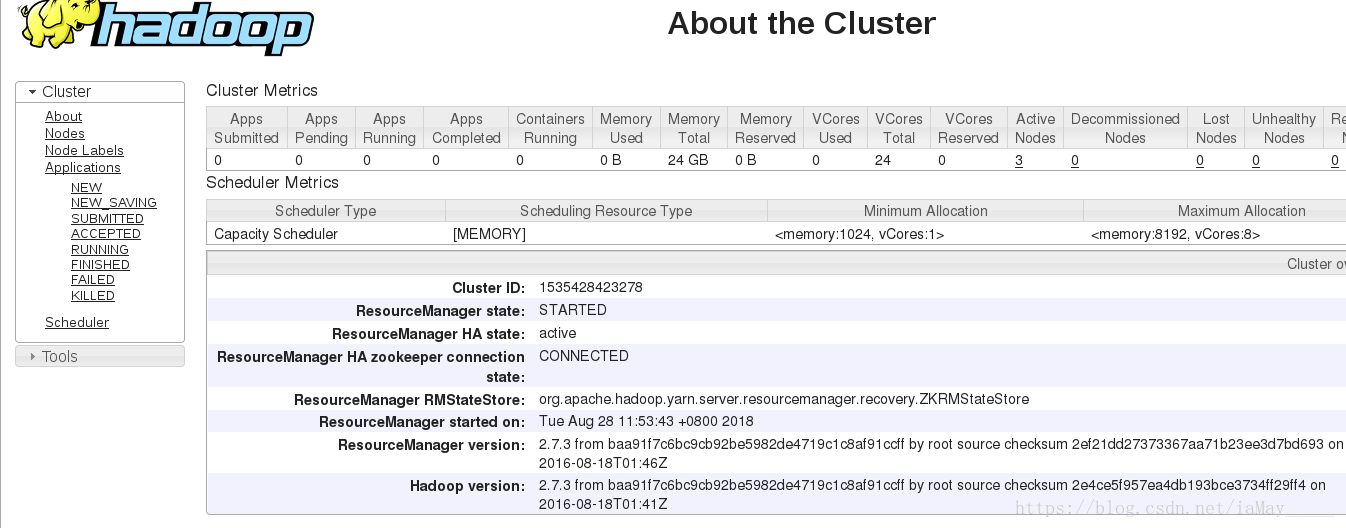
依旧为一台服务器运行
测试高可用性能
[root@server1 hadoop]# jps
8752 NameNode
9394 ResourceManager
9050 DFSZKFailoverController
9466 Jps
[root@server1 hadoop]# kill -9 9394- 1
- 2
- 3
- 4
- 5
- 6
server5成功接管
server1重新开启服务即可
[root@server1 hadoop]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-root-resourcemanager-server1.out- 1
- 2
hbase的使用
Hbase 分布式部署
1) hbase 配置
$ tar zxf hbase-1.2.4-bin.tar.gz
$ vim hbase-env.sh
export JAVA_HOME=/home/hadoop/java
#指定 jdk
export HBASE_MANAGES_ZK=false
#默认值时 true,hbase 在启动时自动开启 zookeeper,如需自己维护 zookeeper 集群需设置为 false
export HADOOP_HOME=/home/hadoop/hadoop #指定 hadoop 目录,否则 hbase无法识别 hdfs 集群配置。
——————————————————————————————————————————————————————————————————————————
vim hbase-site.xml
<configuration>
<!-- 指定 region server 的共享目录,用来持久化 HBase。这里指定的 HDFS 地址
是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致。 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
<!-- 启用 hbase 分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Zookeeper 集群的地址列表,用逗号分割。默认是 localhost,是给伪分布式用
的。要修改才能在完全分布式的情况下使用。 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.0.2,172.25.0.3,172.25.0.4</value>
</property>
<!-- 指定数据拷贝 2 份,hdfs 默认是 3 份。 -->这一步可以不用配置 默认三份即可
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定 hbase 的 master -->
<property><name>hbase.master</name>
<value>h1</value>
</property>
</configuration>
$ cat regionservers(zookeeper节点ip)
172.25.0.3
172.25.0.4
172.25.0.2
————————————————————————————————————————————————————————————————
启动 hbase
主节点运行:
$ bin/start-hbase.sh
[hadoop@server1 hbase]$ jps
6559 Jps
2163 NameNode
1739 DFSZKFailoverController
5127 ResourceManager
1963 HMaster
备节点运行:
[hadoop@server5 hbase]$ bin/hbase-daemon.sh start master
1191 NameNode
3298 Jps
1293 DFSZKFailoverController
2757 ResourceManager
1620 HMaster
浏览器查看即可- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口
上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示
信息的界面。
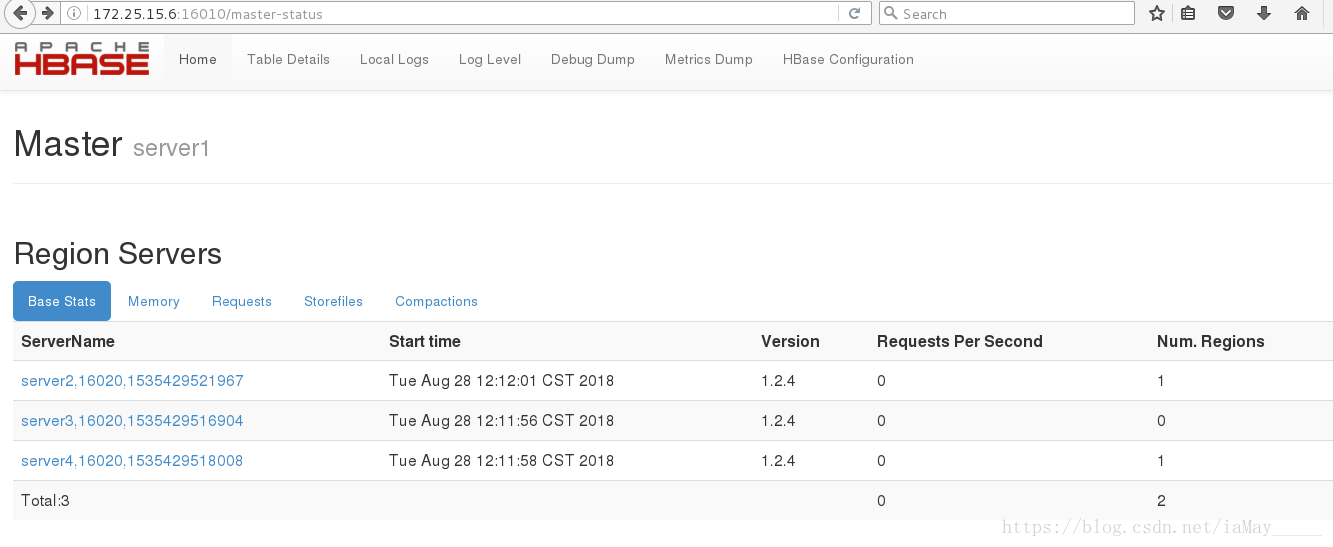
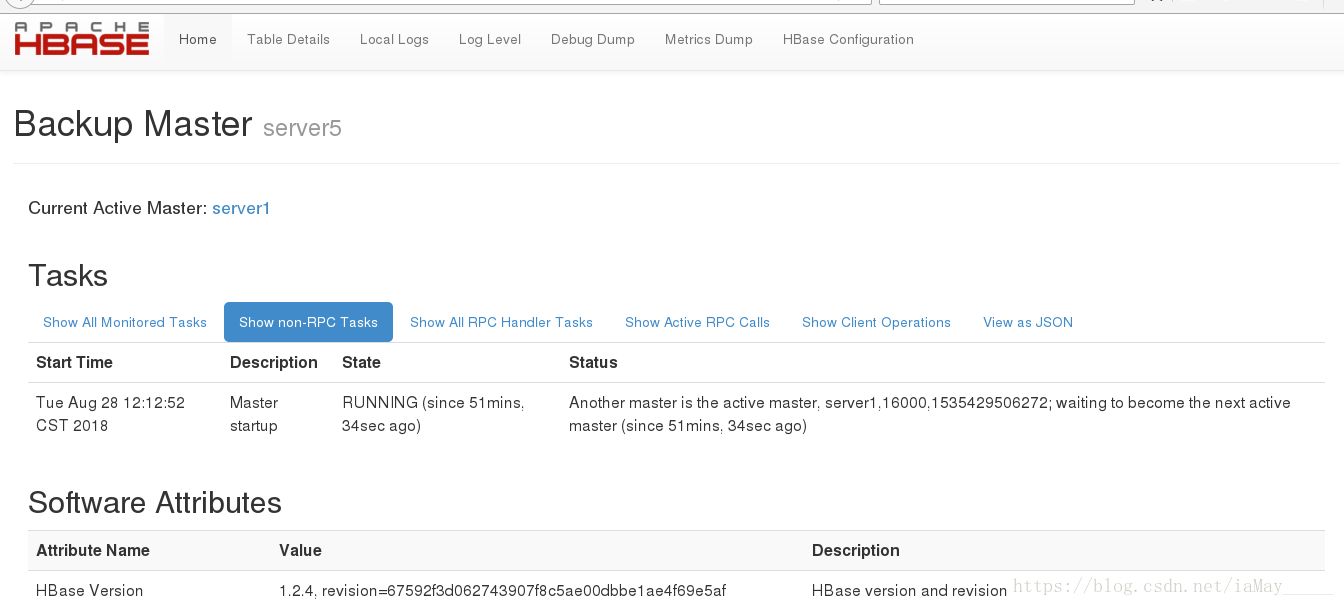
测试故障切换 kill进程即可
测试数据
[root@server1 hbase-1.2.4]# bin/hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.4, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016
hbase(main):001:0>
——————————————————————————————————————————————————————————————————————
hbase(main):001:0> create 'test', 'cf'
——————————————————————————————————————————————————————————————————————
hbase(main):005:0> list "test"
TABLE
test
1 row(s) in 0.0060 seconds
=> ["test"]
——————————————————————————————————————————————————————————————————
hbase(main):006:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.3610 seconds
hbase(main):007:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0260 seconds
hbase(main):008:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0170 seconds
————————————————————————————————————————————————————————————————————
查看数据是否添加
[root@server5 hadoop]# bin/hdfs dfs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 2018-08-28 12:12 /hbase
drwxr-xr-x - root supergroup 0 2018-08-28 11:48 /user
添加成功
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
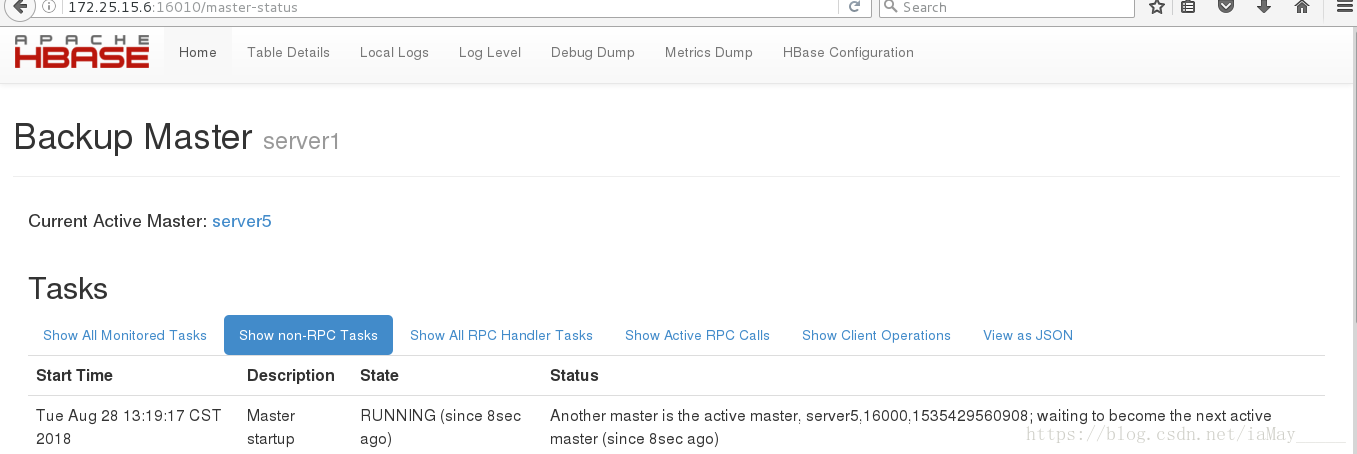
停掉server1 hbase 服务 测试高可用性能
server5 成功接管 ok
开启server hbase 变为备用节点
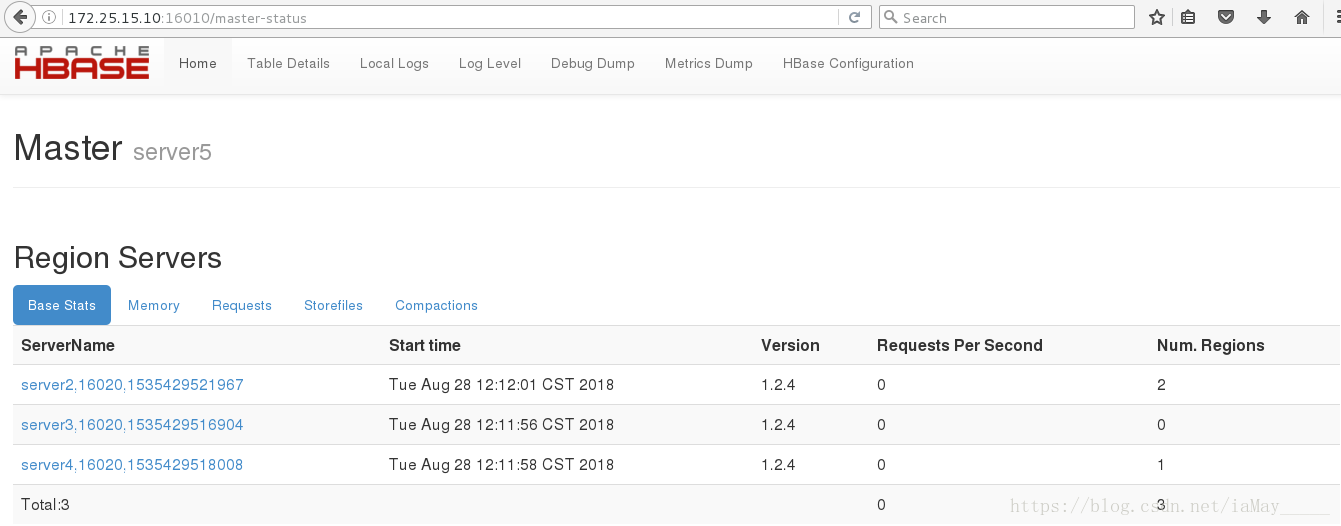
转载请注明:SuperIT » Hadoop zookeeper高可用HA配置





